
Customer support and contact center platforms generate terabytes of voice data every day, but most enterprises still underutilize it. Traditionally, call recordings were archived for compliance or occasional QA audits, but with modern AI infrastructure, those same conversations can now become one of the most valuable operational intelligence datasets inside an organization.
A modern Call Transcription Analytics pipeline is no longer just about converting speech into text. The real value comes from understanding customer intent, measuring sentiment, extracting operational KPIs, identifying churn risk, generating summaries and enabling semantic search over millions of conversations using GenAI and vector intelligence.
What makes this interesting from an engineering perspective is the combination of real-time streaming systems, GPU inference pipelines, large language models and cloud-native analytics warehouses like Snowflake working together in a low-latency architecture.
An enterprise-grade architecture usually looks something like this:
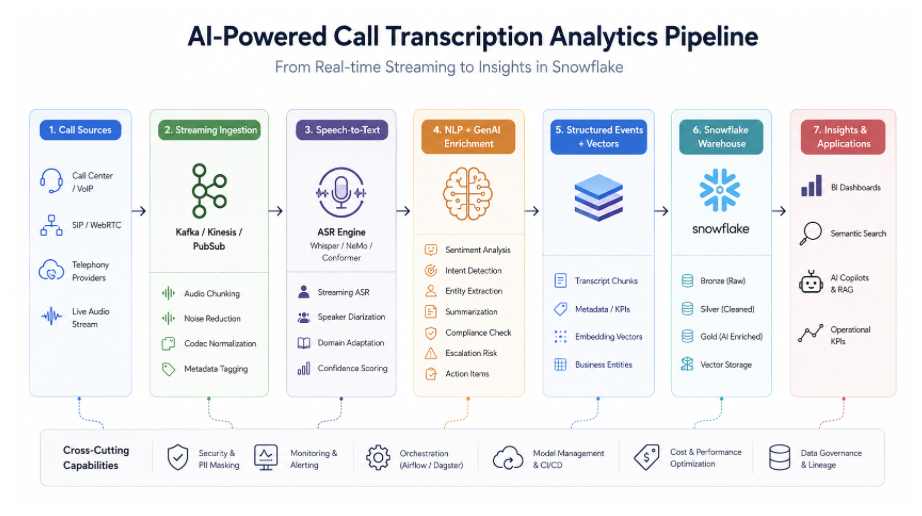
The pipeline itself is fully event-driven. Every stage emits structured events that downstream systems consume independently. This decoupled design becomes extremely important at scale because speech inference, NLP enrichment and warehouse ingestion all have different latency and compute characteristics.
Real-Time Audio Streaming Layer
The first stage of the system begins with ingesting live audio streams from telephony platforms such as Twilio, Genesys, SIP providers, or internal VoIP systems. Audio is usually streamed continuously in small chunks, often between 500 milliseconds and 2 seconds, to minimize transcription latency.
Most architectures introduce a dedicated streaming backbone using technologies like Apache Kafka or Amazon Kinesis. This layer acts as the central nervous system of the platform.
Before transcription even starts, the pipeline often performs preprocessing operations including codec normalization, silence removal, channel separation and noise reduction. In noisy environments this preprocessing stage significantly improves ASR accuracy.
One thing teams often underestimate is handling partial transcript state. Streaming ASR systems continuously revise words as additional context arrives. A sentence generated at second 2 might be slightly modified at second 5 once the model has more confidence. That means downstream consumers cannot assume transcripts are immutable append-only records.
Speech-to-Text and Streaming ASR
Once audio packets enter the inference layer, they are processed by real-time Automatic Speech Recognition (ASR) systems. Modern ASR pipelines are mostly transformer-based and commonly use models derived from Whisper, Conformer, or Nvidia NeMo architectures.
Inference usually runs on GPU-backed microservices optimized for low-latency streaming workloads. Some enterprises deploy dedicated inference clusters because ASR quickly becomes one of the most compute-intensive stages in the entire platform.
A major challenge in production systems is domain adaptation. Generic speech models struggle badly with industry-specific terminology. Healthcare calls, insurance claims, banking acronyms and internal product names often produce poor transcriptions unless custom vocabularies or phrase boosting are implemented.
Speaker diarization is another critical component. The system must correctly identify who is speaking — customer, support agent, supervisor, or automated IVR. Without speaker attribution, downstream sentiment analysis becomes almost meaningless.
At this stage, the pipeline typically emits transcript events like:
| { “call_id”: “CX-4412”, “speaker”: “customer”, “text”: “I was charged twice for the same subscription”, “confidence”: 0.94, “timestamp”: “2026-05-12T18:22:11Z” } |
These transcript streams become the input for the AI enrichment layer.
NLP and GenAI Enrichment Layer
This is where the pipeline starts becoming intelligent rather than simply transcription-based.
Once transcript chunks are available, NLP and GenAI services begin extracting semantic meaning from the conversation in near real time. Most modern systems combine traditional NLP models with LLM-based reasoning pipelines.
The enrichment layer typically generates:
● sentiment scores
● customer intent
● escalation probability
● compliance violations
● entity extraction
● topic classification
● call summaries
● action items
● churn indicators
● empathy scoring
Traditional NLP classifiers are still extremely valuable here because they are cheap, deterministic and fast. LLMs are usually reserved for deeper reasoning tasks like summarization or conversational understanding.
A common architecture pattern is using lightweight transformer classifiers first, then selectively routing only important conversations into expensive LLM inference pipelines. Otherwise token costs can explode very quickly across millions of calls.
For example, if a transcript shows strong negative sentiment combined with cancellation-related keywords, the system may trigger a larger GenAI workflow for advanced retention-risk analysis.
LLM-Based Conversational Intelligence
Large Language Models changed transcript analytics quite dramatically because they introduced contextual understanding instead of simple keyword matching.
Earlier systems relied heavily on static rules and phrase dictionaries. Modern GenAI pipelines can reason across entire conversations and infer customer frustration even if the customer never explicitly says they are upset.
An LLM prompt might look something like this:
| Analyze this support call transcript. Extract: – customer intent – resolution outcome – escalation probability – customer satisfaction likelihood – follow-up actions – compliance risks |
The output is then normalized into structured JSON events:
| { “intent”: “billing_dispute”, “sentiment”: “negative”, “resolution_status”: “pending”, “escalation_probability”: 0.81, “follow_up_actions”: [ “refund request”, “manager escalation” ] } |
This structured representation is what eventually powers downstream analytics dashboards, operational KPIs and AI copilots.
One thing many companies learn the hard way is that fully autonomous LLM reasoning is risky in production. Hallucinated summaries, inconsistent outputs and prompt drift can create major operational problems. Mature architectures therefore combine deterministic business rules with selective GenAI augmentation instead of relying purely on prompting.
Embeddings and Semantic Search
One of the biggest evolutions in transcript analytics is the introduction of vector embeddings.
Instead of relying only on keyword-based search, transcript chunks are converted into dense semantic vectors using embedding models. These vectors capture meaning and contextual similarity across conversations.
This enables use cases that traditional SQL search simply cannot handle.
For example:
“Find calls similar to customers frustrated about delayed mortgage approvals even if they never explicitly mentioned the word delay.”
Embedding similarity search handles this surprisingly well because semantic meaning is preserved mathematically inside vector space.
Modern systems often generate:
● transcript embeddings
● summary embeddings
● customer interaction embeddings
● issue-resolution embeddings
These embeddings are stored either in vector databases or directly inside platforms like Snowflake which increasingly support vector-native workloads.
This layer becomes extremely important for Retrieval-Augmented Generation (RAG) systems where AI copilots need to retrieve similar historical conversations before generating responses.
Warehouse Ingestion and Analytics
After enrichment is complete, the platform converts all transcript intelligence into structured analytics events and loads them into warehouse systems.
Most companies implement a medallion-style architecture:
● Bronze layer for raw transcripts
● Silver layer for cleaned conversational data
● Gold layer for AI-enriched business intelligence
This separation is important because LLM inference is expensive and organizations usually want immutable raw data preserved independently from derived AI outputs.
A typical warehouse record might include:
| { “call_id”: “CX-4412”, “agent_id”: “A882”, “duration_sec”: 713, “intent”: “refund_request”, “sentiment_score”: -0.72, “resolution_status”: “unresolved”, “summary”: “Customer reported duplicate billing issue”, “embedding_vector”: […] } |
Once data reaches the warehouse, analytics teams can build advanced operational dashboards around:
● CSAT prediction
● average handle time
● repeat call frequency
● escalation trends
● compliance monitoring
● churn probability
● agent performance
● empathy scoring
What becomes interesting is that transcript analytics gradually shifts from retrospective reporting into real-time operational intelligence.
The most advanced platforms do not wait until the call ends.
Instead, inference happens during the conversation itself.
Streaming AI systems can detect customer frustration in real time, recommend retention offers to agents, surface knowledge-base articles dynamically, or alert supervisors during escalation scenarios.
This requires extremely low latency infrastructure because the AI must react before the customer disconnects.
A typical latency budget might look like:
| Stage | Latency |
| Audio chunking | 200ms |
| ASR inference | 800ms |
| NLP enrichment | 400ms |
| LLM reasoning | 1-2 sec |
| Warehouse sync | <5 sec |
Designing around these latency constraints becomes one of the hardest engineering challenges in large-scale AI systems.
Challenges in Production Systems
Building demo pipelines is relatively easy. Building enterprise-grade production systems is much harder.
One major issue is hallucination risk. LLM-generated summaries sometimes include statements that were never actually spoken in the conversation. In regulated industries like healthcare or finance, this becomes a serious compliance problem.
Another challenge is cost optimization. Running large models across millions of daily calls can generate extremely high GPU and token expenses. Because of this, many architectures use layered inference strategies where lightweight models filter conversations before expensive GenAI processing occurs.
PII masking is also critical. Sensitive information such as account numbers, SSNs, payment details and addresses must often be redacted before prompts are sent into external LLM systems.
Long conversations introduce additional complexity because transcript sizes frequently exceed model context windows. Chunking, rolling memory strategies and hierarchical summarization are commonly used to solve this issue.
And honestly, this is where most real-world AI architectures become messy. The pipeline ends up being a careful balance between latency, cost, inference quality, governance and operational reliability.
Call transcription analytics is evolving into a foundational AI layer for enterprise operations.
The combination of:
● streaming infrastructure
● GPU inference
● transformer-based ASR
● vector embeddings
● GenAI reasoning
● warehouse-native analytics
is fundamentally changing how organizations understand customer interactions.
Conversations are no longer treated as passive recordings sitting in storage. They are becoming structured, searchable and continuously analyzable intelligence streams powering operational decision-making in real time. And that shift is pretty massive.







